Iris Software Perspective Paper
Productionizing Generative AI Pilots
A perspective based on our experience
A perspective based on our experience.
Thank you for reading
By Amit Sharma, Indu Madan, Varun Anand and Mohit Mehrotra at Iris Software
Enterprises have vast amounts of unstructured information such as onboarding documents, contracts, financial statements, customer interaction records, confluence pages, etc., with valuable information siloed across formats and systems.
Generative AI is now starting to unlock new capabilities, with vector databases and Large Language Models (LLMs) tapping into unstructured information using natural language, enabling faster insight generation and decision-making. With a large number of offerings, it is very easy to develop Proofs of Concept (PoCs) and pilot applications. However, to derive meaningful value, the PoCs and pilots need to be productionized and delivered in significant scale. This, in our experience, is difficult and poses significant challenges. The following sections outline the considerations in this process, illustrative architectures for PoCs and productionized Generative AI applications as well as a phased approach that can be taken in this journey.
The Conventional Search Approach
Traditional search methods such as Apache Solr and Lucene have long been our go-to for text-based search. Over time, we’ve added techniques, including NLP and entity recognition, to enhance questioning, answering and searching, making information-retrieval more nuanced.
The Advent of LLMs
The advent of LLMs, exemplified by the publicly-available ChatGPT, has been a game-changer for information retrieval and contextual question answering. As LLMs evolve, they’re not just limited to text. They’re becoming multi-modal, capable of interpreting charts and images.
RAG (Retrieval-Augmented Generation) = Search Engine + Smart Assistant Combined
RAG combines retrieval with generation to provide relevant and context-aware answers to user queries. It enhances capabilities; it doesn’t just find the documents, it will read them and create a tailored answer for us. Multi-modal and agent capabilities of LLMs and related technologies enable extraction of information from diverse sources and support of user needs beyond search and summarization.
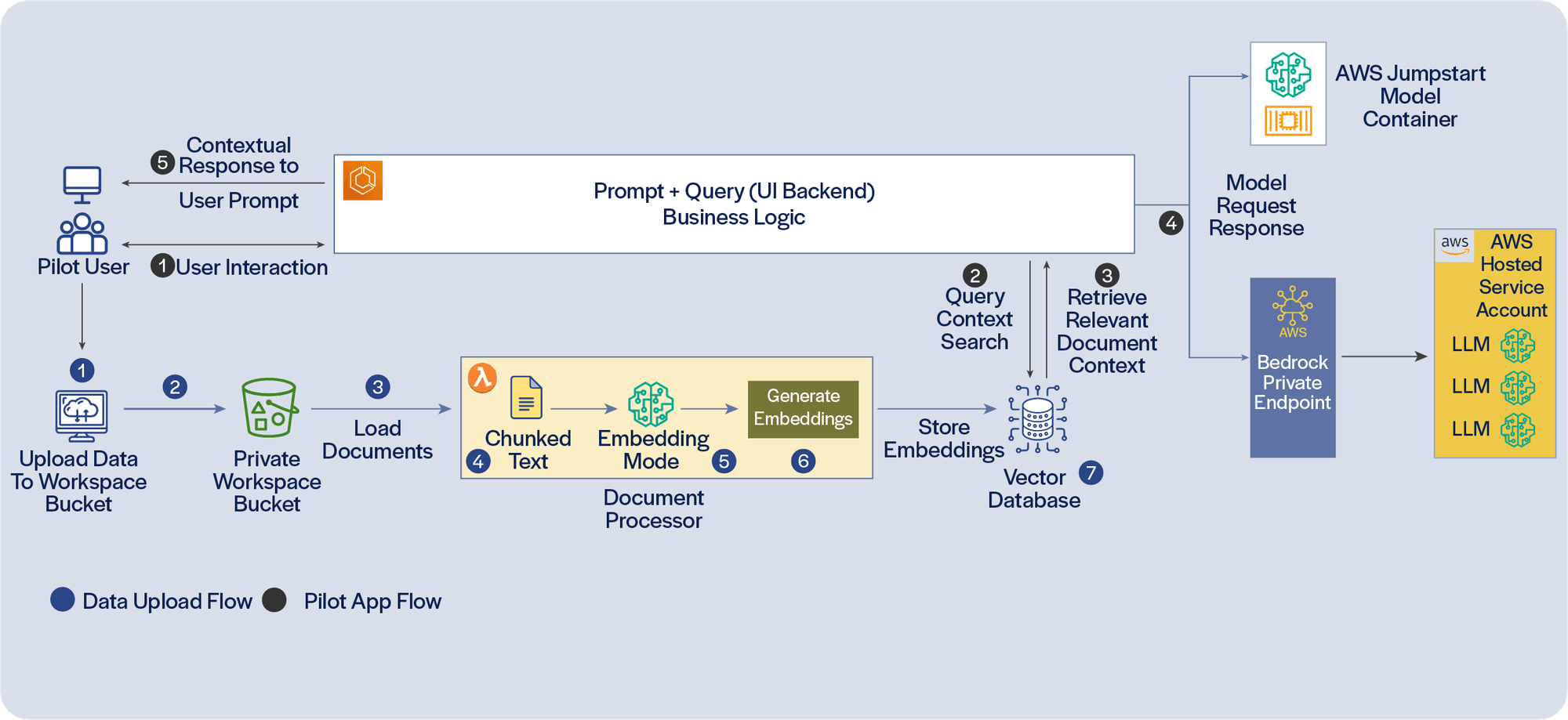
Development of Gen AI PoCs and pilot applications can be relatively easy. The following outlines simple ways to get started leveraging a few AWS Managed Services.
Start with a handful of users and small subset of documents.
Utilize step functions for document processing, basic Flask service for the frontend.
Lambda function for prompt and query.
AWS Bedrock and Jumpstart for LLMs access.
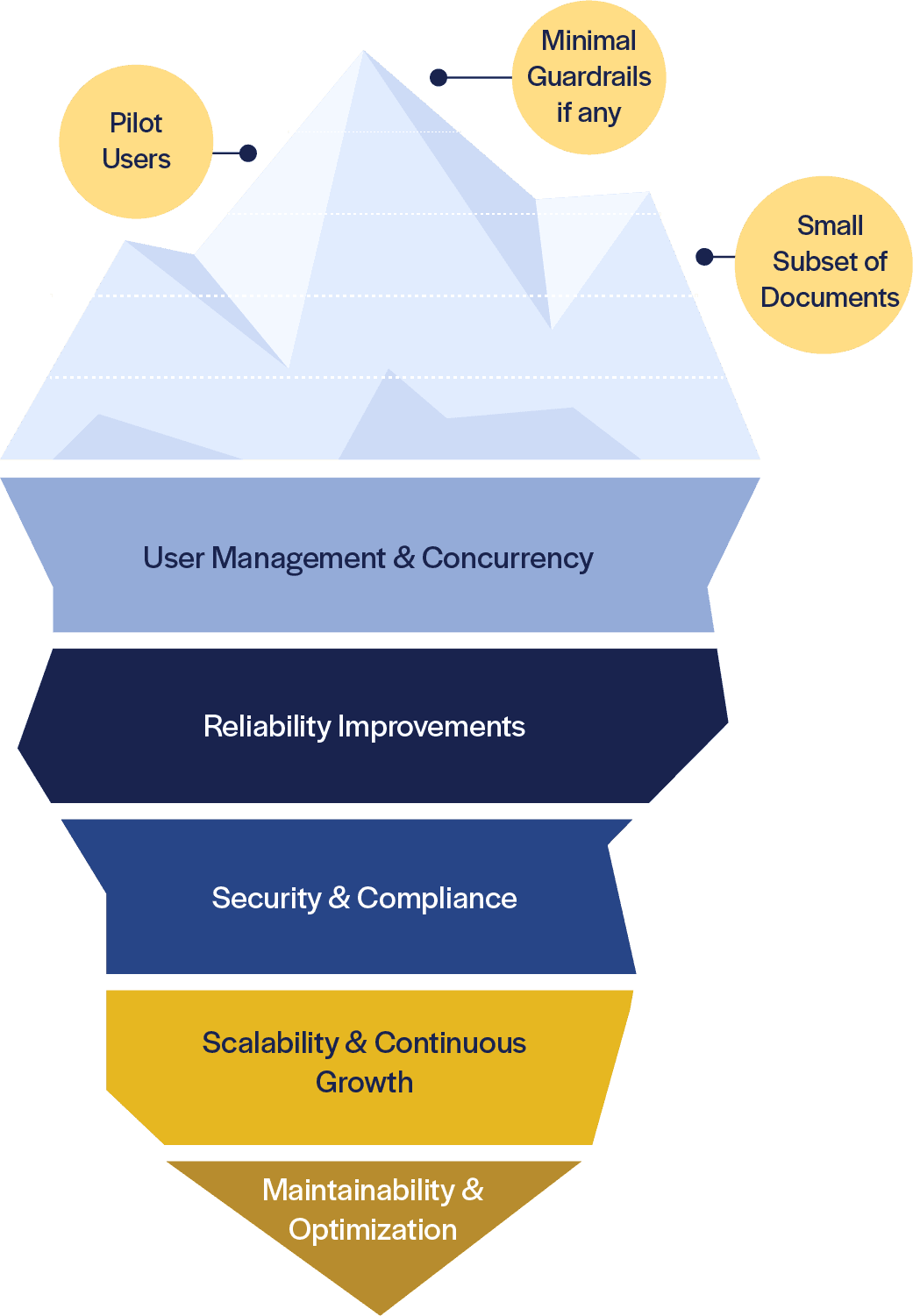
PoCs/pilots deal with only the tip of the iceberg. Productionizing needs to address a lot more that does not readily meet the eye. To imbue Generative AI PoCs and pilots with production-ready capabilities for many concurrent users, one must consider the following:
Caches to store and utilize user context-aware in shared sessions. Role-based pre-filtering of documents and/or sections.
Ensure knowledge-base and response coherence and consistency. Handle LLM exceptions and other failures gracefully.
Establish AI safeguards and ensure data privacy.
Utilize queues to leverage shared LLM sessions across multiple concurrent users and caches for recent/ frequent requests and responses across users. Support large-scale cost-effective retrieval and efficient generation.
Ensure knowledge-base freshness through ongoing updates and synchronization with enterprise and external sources. Establish model performance-monitoring and fine-tuning.
The following sections elaborate on these.
User Management and Concurrency
Robust infrastructure-design for scaling from a handful of PoC users to the higher production volume of concurrent users.
Session management for multiple users becomes vital for a personalized experience.
Multiplexing LLM API tokens across multiple users is crucial for efficient management of LLM service API calls.
Caches for context-preservation and information-isolation between users for a trusted multi-user Gen AI experience.
Load balancing and request queuing is essential for sharing-sessions across users maintaining performance and service availability.
Implementing custom rate-limiting and quota management for ensuring fair resource allocation and maintaining service quality.
Optimizing retry mechanisms and back-off strategies is essential for improving application resilience and transient disruptions.
Reliability, Security and Compliance
Consistently generating correct responses that follow user-provided instruction and avoiding production of factually-incorrect and unrelated responses – aka hallucination - in a reliable manner is a significant challenge.
Reliably and accurately retrieving relevant information poses a notable hurdle due to the diverse nature of questions and information sources, including varied document formats, charts and table structures, images and domain-specific contextual details.
Interpreting temporal queries with correct time-based data ranges, particularly for historical or time-sensitive information, in a reliable manner is challenging.
Implementation of user authentication and authorization needs to comply with enterprise requirements.
Role-based access control: Enforcing controls for which roles can ask specific types of questions or access certain data aligning with information-security requirements is quite formidable.
Personally Identifiable Information (PII) Data Protection: Implementing logic to detect and redact PII in both the knowledge-base and generated responses requires sophisticated mechanisms.
Complying with audit requirements: A regulatory setting creates complex hurdles for deciding which query logs are used to record and provide transparent and explainable AI responses.
Preventing direct and indirect prompt injection, and managing prompt sanitization and other vulnerabilities, raises substantial concerns.
Scalability, Performance, Ongoing Optimization and Evolution
Scaling performance for vector search as a document corpus grows in production volume presents formidable technical difficulties.
Optimizing token usage and context window management presents a crucial scalability hurdle for RAG applications.
Implementing tiered caching, intelligent eviction based on context and query patterns to context Approach pruning strategies to incrementally update caches presents significant work.
Balancing LLM usage costs with application scalability presents a substantial financial hurdle as user base and context volume grows as well as the demand for more inference speed and size.
Managing and keeping knowledge-bases for retrieval up-to-date can be challenging when going from a few documents in PoC to thousands in a production setting.
Maintaining retrieval accuracy, LLM speed, generation-quality and managing cost presents a complex optimization challenge.
Handling multi-lingual and multi-modal data in the retrieval process can present certain challenges, e.g., many documents in the bank are in English and French.
Upgrading models can introduce compatibility issues with existing prompts, requiring careful management.
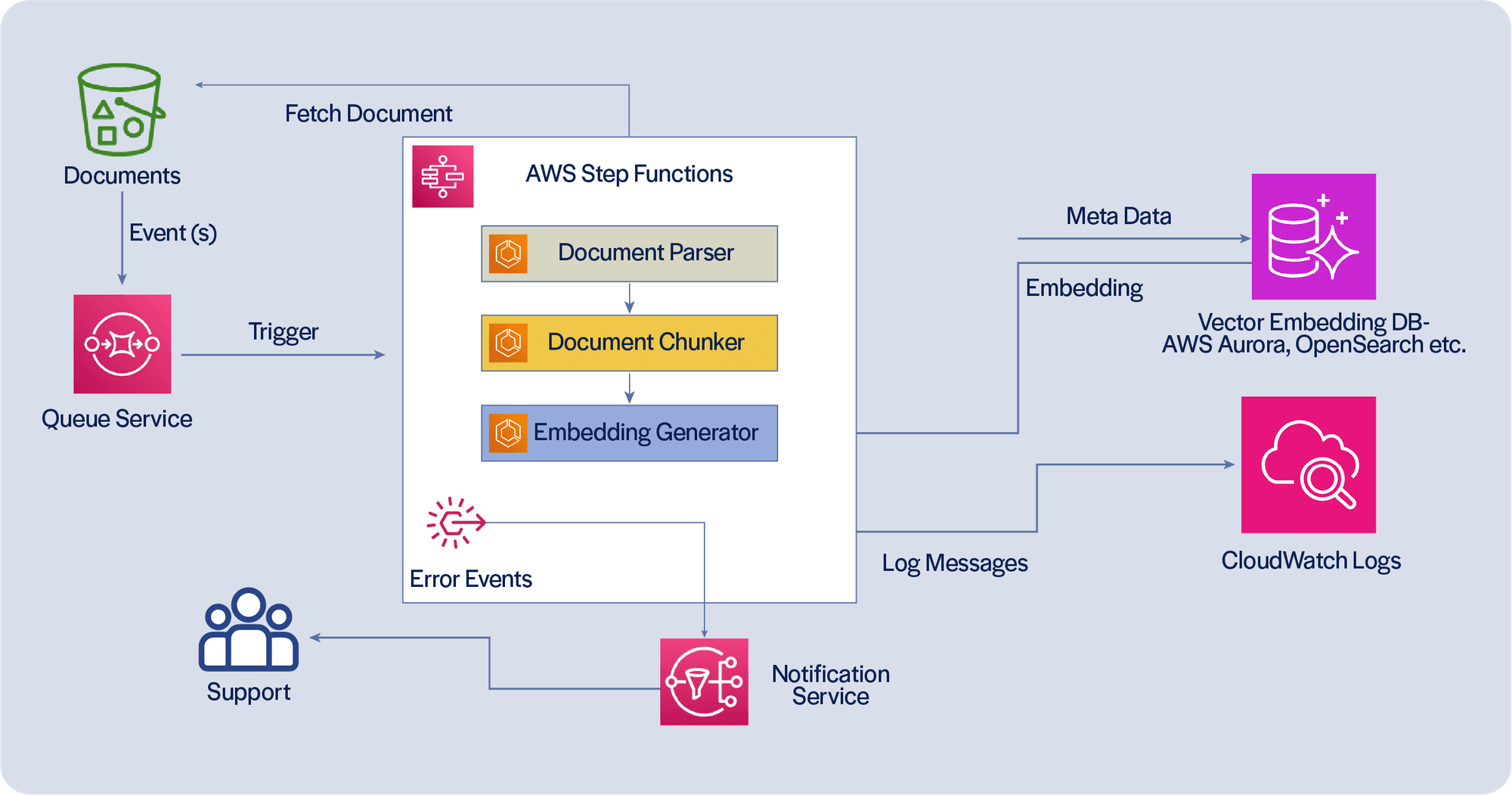
Scaling Information Extraction from Larger Volume of Documents and Other Unstructured Sources
To scale extraction and indexing information, we need to establish a pipeline that, ideally, would be driven by events, new documents generated and available, possibly through an S3 document store and SQS to initiate parsing of documents for metadata, chunking, creating vector embedding and persisting metadata and vector embedding to suitable persistence stores. There is a need for logging and exception-handling, notification and automated retries when the pipeline encounters issues.
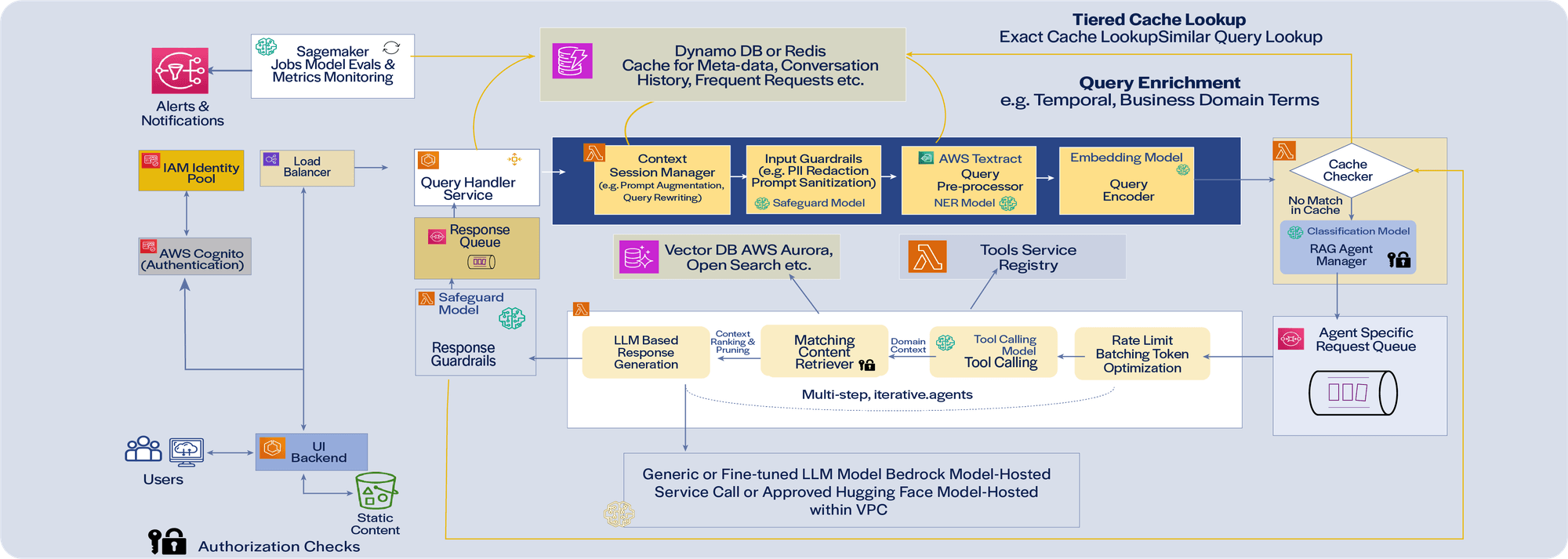
Illustrative Architecture for RAG-based Retrieval using Multiple Agents and Iterative Response Generation Approach
Note: The above diagram is illustrative. There are multiple choices for many of the components above. For instance, ECS or EC2 could be used instead of Lambda for various services. Similarly, many services (e.g. Textract) will involve API invocations. These have been left out to keep the architecture illustrative. There would be keys/tokens for various APIs/services – which would need to be stored, retrieved and used in a manner compliant with enterprise policies and practices. There would be logging, monitoring, and so on, potentially integrating with appropriate libraries and services; these have also been left out to keep the illustration relatively simple.
Build, deploy and initial implementation to demonstrate the art of the possible. Limited scope rollout in a live setting and assess user experience.
Limited user group + subset of documents + baseline metrics established.
Engage a small, targeted group of business users to participate in the initial deployment.
Select a specific and manageable subset of documents, representative of common scenarios, for the pilot.
Focus on testing and validation of the application functionality and performance.
Define and measure key baseline metrics to track user engagement
Basic user management + API handling
Add momentum through reliability. Build enthusiasm, engage influencer users, evangelize and collect feedback.
Augment additional context with metadata engine for reliability and consistency in response.
Implement guardrail model to ensure consistent, reliable and PII-safe responses.
Implement modular pipelines for reliable data ingestion and processing.
Mitigate incorrect/vague responses and edge-cases through domain-specific context and fine-tuning.
Implement custom rate limiting and quota management.
Fallback mechanisms/graceful handling for API failures.
Automated model evaluations on conversation history.
Use streaming response.
Implement efficient caching strategies to address latency and manage costs.
Add model router to optimize various edge-case scenarios and improve experimentation with newer/cheaper models.
Implement LLM performance-monitoring.
While developing pilot applications using Generative AI is easy, teams need to carefully work through a number of additional considerations to take these applications to production, scale the volume of documents and the user-base, and deliver full value. It would be easier to do this across multiple RAG applications, utilizing conventional NLP and classification techniques to direct user requests to different RAG pipelines for different queries. Implementing the capabilities required around productionizing Generative AI applications using LLMs in a phased manner will ensure that value can be scaled as the overall solution architecture and infrastructure is enhanced.
This perspective paper is written by Amit Sharma, Indu Madan, Varun Anand and Mohit Mehrotra at Iris Software.
Amit Sharma, of the Data & Analytics Practice at Iris Software, is a seasoned Machine Learning (ML) professional and has contributed to numerous projects ranging from large-scale personalization to cutting-edge NLP. With extensive experience in on-premises and cloud-based solutions, Amit holds multiple patents in ML and has over 20 years of software engineering experience. His expertise extends to the critical area of operationalizing models.
Indu Madan, Iris Software Automation Practice, has more than 15 of years of experience in software product engineering as well as software service experience in industrializing ML and AI models, Generative AI, and digital transformation in several verticals.
Varun Anand, of the Automation Practice at Iris Software, is a seasoned professional with multiple years of experience in ML, computer vision and intelligent automation projects. He has designed and implemented complete production-grade ML and Generative AI pipelines for solving business challenges. He holds patents for a risk data
aggregation framework and payment on-time algorithm.
Mohit Mehrotra, Iris Software Data & Analytics Practice, is an experienced software architect closely involved in platform engineering and technology modernization initiatives within banking, retail and logistics domains. He is passionate about leveraging the power of emerging technologies and Generative AI to accelerate application development cycles for Iris customers.
Iris Software has been a trusted software engineering partner to Fortune 500 companies for over three decades. We help clients realize the full potential of technology-enabled transformation by bringing together a unique blend of domain knowledge, best-of-breed technologies, and experience executing essential and critical application development engagements. With over 4,300 skilled professionals, Iris builds mission-critical technology solutions across banking, financial services, insurance, life sciences, logistics, and manufacturing. Iris offers comprehensive services across Application and Product Engineering, Cloud Migration and native Cloud Development, DevSecOps, SRE, Data Engineering, AI/Gen AI/ML/NLP, Data Science, Quality Engineering, Intelligent Automation, Low-code/No-code Development etc.
Learn more about our Generative AI capabilities at:https://www.irissoftware.com/news-events/the-2020s-the-decade-of-artificial-intelligence
Click here to read about the milestones of our 30-year journey.