Delivering Intelligence with Speed and Scale
Iris Software Perspective Paper
Thank you for reading
By Prem Swarup Jethalal, Vice President - Leader of the Data & Analytics Practice at Iris Software
Automating organizational processes, establishing systems of record, collating and analyzing information from across the organization were key drivers for technology initiatives for the last three to four decades. Applying Artificial Intelligence (AI) and Machine Learning (ML) and delivering intelligence is becoming the focus of this decade.
AI and ML capabilities have been in use for some time but have not delivered to potential due to various factors, such as infrastructural constraints, siloed sandboxes of data, and hard separation of data science from data engineering skills and platforms, etc.
Further, over the past decade, in addition to structured data, through a number of digital initiatives, organizations have collated a lot of information in unstructured and semi-structured formats (e.g., digitized contracts, audio/video of customer interactions). The opportunities to apply established and emerging AI/ML techniques and models to this wide variety of information and derive intelligence and enhanced insights have significantly increased.
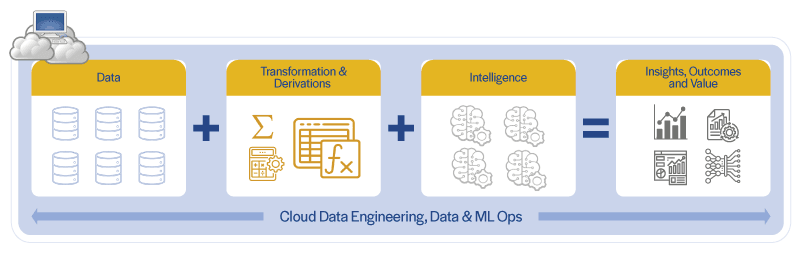
Cloud and the evolving technologies around Data Engineering, Data & ML Ops, Data Science, and AI/ML (e.g., Generative AI) offer a significant opportunity to overcome these limitations and deliver intelligence with speed and at scale.
This paper explores the benefits, challenges, and best practices for scaling various stages of deriving intelligence from data on cloud environments.
Traditional data technologies were largely limited to structured data and relational models. Organizations adopted appliance-based data warehousing technologies to deal with increasing data volumes but have realized that, in addition to being very expensive to scale, they are not well-suited for bringing together structured and semi/unstructured information for further derivations, analysis and intelligence. There are many external sources of information that can complement internal sources to produce a more complete view.
Building on Hadoop and Big Data technologies, cloud offers highly scalable and affordable object storage services (e.g., AWS S3) that can bring together structured and semi/unstructured information from internal and external sources for further derivations, and run AI/ML models for generating intelligence at scale.
Object storage uses a flat, scalable architecture that does not include indexing or table joins, which reduces the storage overhead associated with relational databases. This also can allow data science teams to BYOD (bring your own data) during the experimentation phase.
While traditional ETL vendors support cloud deployment, many firms are choosing cloud providers (e.g., Azure Data Factory, AWS Glue) offering orchestration services (e.g., Step Functions). In addition to batch data, cloud enables cost effective acquiring, cleansing and storing of large volumes of data from streaming sources. These services allow data science engineering teams to work in parallel to establish the pipes and processes to acquire data on an ongoing basis.
Overall, cloud storage makes cost-effective storage of and access to large volumes of data feasible. Cloud architecture also enables data sharing along with federated ownership.
While the number and sophistication of AI/ML models available have increased and become easier to deploy, train/tune, and use, they need information at scale to be transformed to features.
Transformations and derivations can be easily scaled on cloud. Spark/PySpark are the de facto technologies. Distributed processing is Spark’s strength and understanding how Spark-distributed datasets work can enable scale in transformations and derivations.
Cloud also enables in-stream calculations/transformations using lambda functions.
Persisting calculations, and updating them in the catalog, can make transformations and calculations first-class-citizens of scalable intelligence architectures, supporting pipelines of features and models coming together to support the generation of more sophisticated intelligence.
Scale Intelligence
Delivering intelligence in scale would require more than just data lakes and lake-houses. It also requires the overall ability to support multiple modeling/data science teams working on multiple problems/opportunities concurrently.
Data Science Engineering and Data & ML Ops are key to enable scaling of the intelligence part of the data monetization lifecycle. Teams need to understand data science/modeling lifecycles to effectively scale intelligence.
ML Ops allows for scaling intelligence by standardizing and automating the ML project lifecycle. (Read more on this in the Iris Software Perspective Paper, Machine Learning Operations: Overcoming Challenges in Migration to the Cloud, by Amit Sharma, Senior Director — Data Science.)
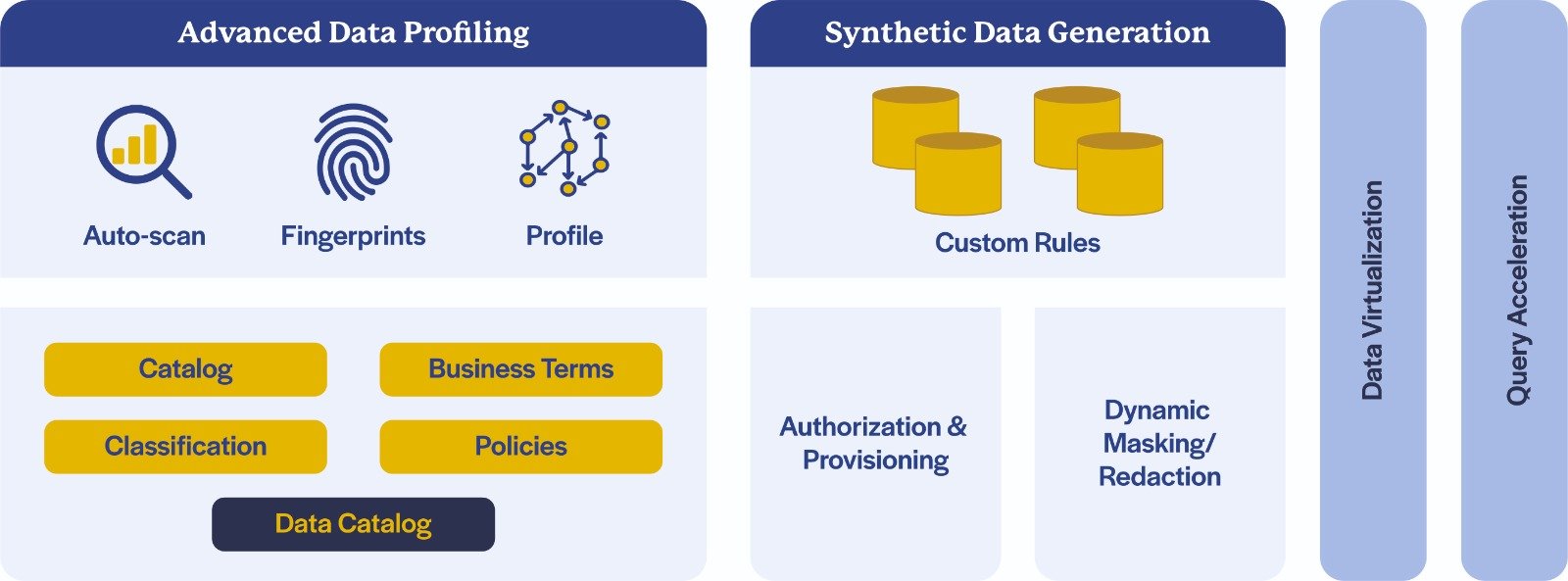
There are other critical capabilities which enable scaling of data science; they are listed, as well as depicted, in the schematic below:
Intelligent catalog that brings together data, derivations and intelligence.
Data profile and synthetic data generation to support development-minimizing use of production data or scaling training/testing data.
Data Ops to ensure strong SLAs and quality data through the lifecycle and across environments.
Continuous monitoring of data quality including alerts for anomalies or data drift.
Data lineage – keeping a record of where data comes from and how it's transformed.
Data virtualization and query acceleration to minimize duplication of data across ML initiatives.
In conclusion, organizations demand intelligence in scale and at speed. Emerging technologies like Generative AI demand more powerful infrastructure (e.g., GPU farms). Cloud technologies and services enable these. With support for Python across the intelligence lifecycle, it has become easier to bring together data engineering and data science teams that are easier to provision and use in cloud.
This perspective paper is written by Prem Swarup Jethalal, Vice President - Leader of the Data Engineering, Data Science & Analytics Practices at Iris Software. Prem and his team are actively engaged in architecting, designing, and implementing cloud-native data and analytics infrastructures and solutions to support various operational, analytics and machine-learning workloads. Prem has provided thought and execution leadership to multiple engagements for migrating on-premises operational data stores, data warehouses, data lakes, and Big Data implementations to a public cloud.
Iris Software has been a trusted software engineering partner to Fortune 500 companies for over three decades. We help clients realize the full potential of technology-enabled transformation by bringing together a unique blend of domain knowledge, best-of-breed technologies, and experience executing essential and critical application development engagements.
With over 4,300 skilled professionals, Iris builds mission-critical technology solutions across banking, financial services, insurance, life sciences, and manufacturing. Iris offers comprehensive services and solutions across Data competencies ranging from data engineering, enterprise analytics, data science and data governance.
Click here to read about the milestones of our 30-year journey.
Learn more about our Data & Analytics capabilities at:https://www.irissoftware.com/services/data-analytics